High performance computing for CFD
High Performance Computing for CFD

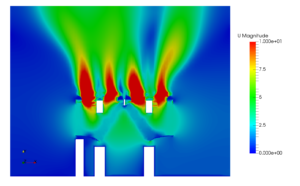
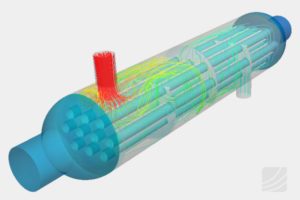
Computational fluid dynamics is a exponentially growing domain in the field of applied sciences. Experimental and analytical methods can only solve relatively simple problems. For instance, analytical methods are actually applied only to 1-dimensional and 2-dimensional problems, whereas experimental methods need lot of time and resources and there are feasibility issues. With the advent of numerical methods like CFD, complex problems were solved in a much shorter time. Thus making CFD very popular tool for solving industrial flow problems.
Power of HPC:
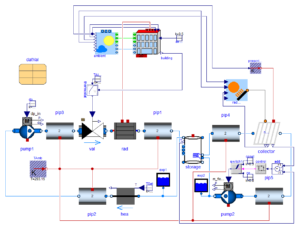
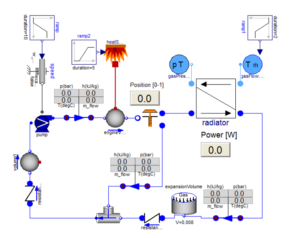
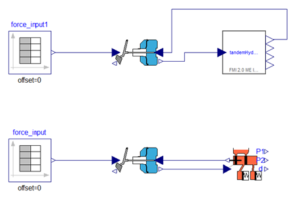
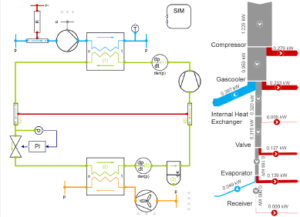
Nowadays, most of the systems have amazing computational speed which is of the order of 10 to the power of 12 floating points per second. There are two types of architectures available with respect to high performance computers. They are vector and symmetric multiprocessing architecture. Since the multiprocessing architecture is cost effective compared to its counterpart it has captured the industry. For instance, if there is a system which has three governing variables which are three dimensional and has one million mesh cells then we need to process nine million cell information per iteration. Parallel platforms and large number of cores have made it possible to solve such a demanding problem within a matter of hours. In commercial solvers the mesh is divided into as many segments as the number of cores (by default), so each core solves one segment. The user may increase the number of segments solved by each block. If N cores are working in parallel, the time for sequential or single cores to run the same problem must be N multiplied by the time taken by each processing unit. Usually this process is challenged by several technical issues such as CPU cache communication, memory bandwidth, and network latency. Engineers and scientists are working hand in hand to overcome the above mentioned hurdles faced by a processor.
In a multiprocessing system because, each processor requires data that is in other domains, the exchange of data between processors or storage is a very critical factor which has to be considered. Explicit methods which are implemented in most of the solvers are relatively easier to parallelize whereas implicit methods are complicated.
Parallelization technique requires a lot of fine-grained communication and there are idle times at the beginning and end of each iteration; this reduces efficiency. So it takes a lot of research and effort in writing codes for solving complex problems.
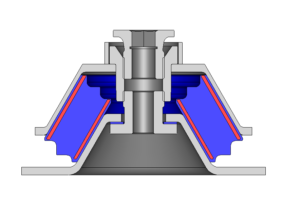
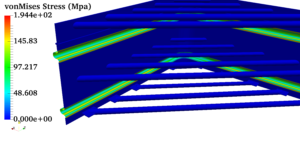
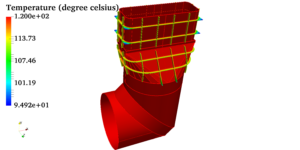
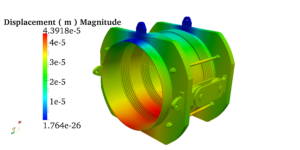
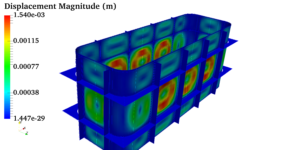 Pressure vessels, pipes, expansion joints etc. are basic equipments for process industries. Pressure vessels are vessels working under internal, external or vacuum pressure, and possibly subjected to high temperature. Proper design and analysis is very important for the pressure vessels, as their failure can cause lot of hazards. Codes/ standards are used in the design phase, followed by analysis to ascertain stresses are within the allowable range. ASME provides wide range of guidelines for the proper design of such vessels.
Pressure vessels, pipes, expansion joints etc. are basic equipments for process industries. Pressure vessels are vessels working under internal, external or vacuum pressure, and possibly subjected to high temperature. Proper design and analysis is very important for the pressure vessels, as their failure can cause lot of hazards. Codes/ standards are used in the design phase, followed by analysis to ascertain stresses are within the allowable range. ASME provides wide range of guidelines for the proper design of such vessels.